En un mundo en que las nuevas tecnologías tienen una repercusión diaria en nuestras acciones, constantemente no paramos de leer nuevos conceptos que pueden sobrepasar-nos. En pocos años hemos pasado de conceptos sencillos como “aplicaciones web”, “digitalización”, “e-commerce” a términos tan desconcertantes como pueden ser “Big Data”, “IoT”, “AI”, “Machine Learning”, etc.
En Eunoia Digital creemos en la necesidad de acercar estos conceptos al público en general para demostrar lo presentes que están en nuestro día a día y la importancia que éstos tienen. Hoy hablaremos sobre el concepto de Machine Learning, qué es, algunas funcionalidades y, como creemos que la mejor manera de aprender es con ejemplos reales, os pondremos algún ejemplo de cómo la podemos aplicar.
¿Qué es el Machine Learning y cómo funciona?
El término Machine Learning hace referencia a una rama de la disciplina científica de la Inteligencia Artificial, esta rama pretende crear sistemas que aprendan de forma automática para predecir resultados.
Para entender como se compone un sistema de aprendizaje automático, vamos a ver los elementos que lo forman aplicados a un ejemplo. Cómo estamos hartos de ejemplos que no se entienden, vamos a aplicar Machine Learning a un suceso que todos conocemos, el Titanic (no, no nos hemos vuelto locos). Para aquellos que no lo conozcan, el Titanic fue un transatlántico que se hundió en el Océano Atlántico en el año 1912 tras colisionar con un iceberg.
Un sistema de Machine Learning aplicado a nuestro ejemplo estaría formado por los siguientes componentes:
Los datos
Los datos son el elemento esencial de todo sistema de aprendizaje, si no tenemos datos, ¡no tenemos nada de dónde aprender! En el caso del Titanic, tenemos el registro de pasajeros que viajaban en el con sus datos de embarque (incluyendo desgraciadamente, si fallecieron o no). Si tenéis curiosidad, podéis consultar los datos en el siguiente enlace.
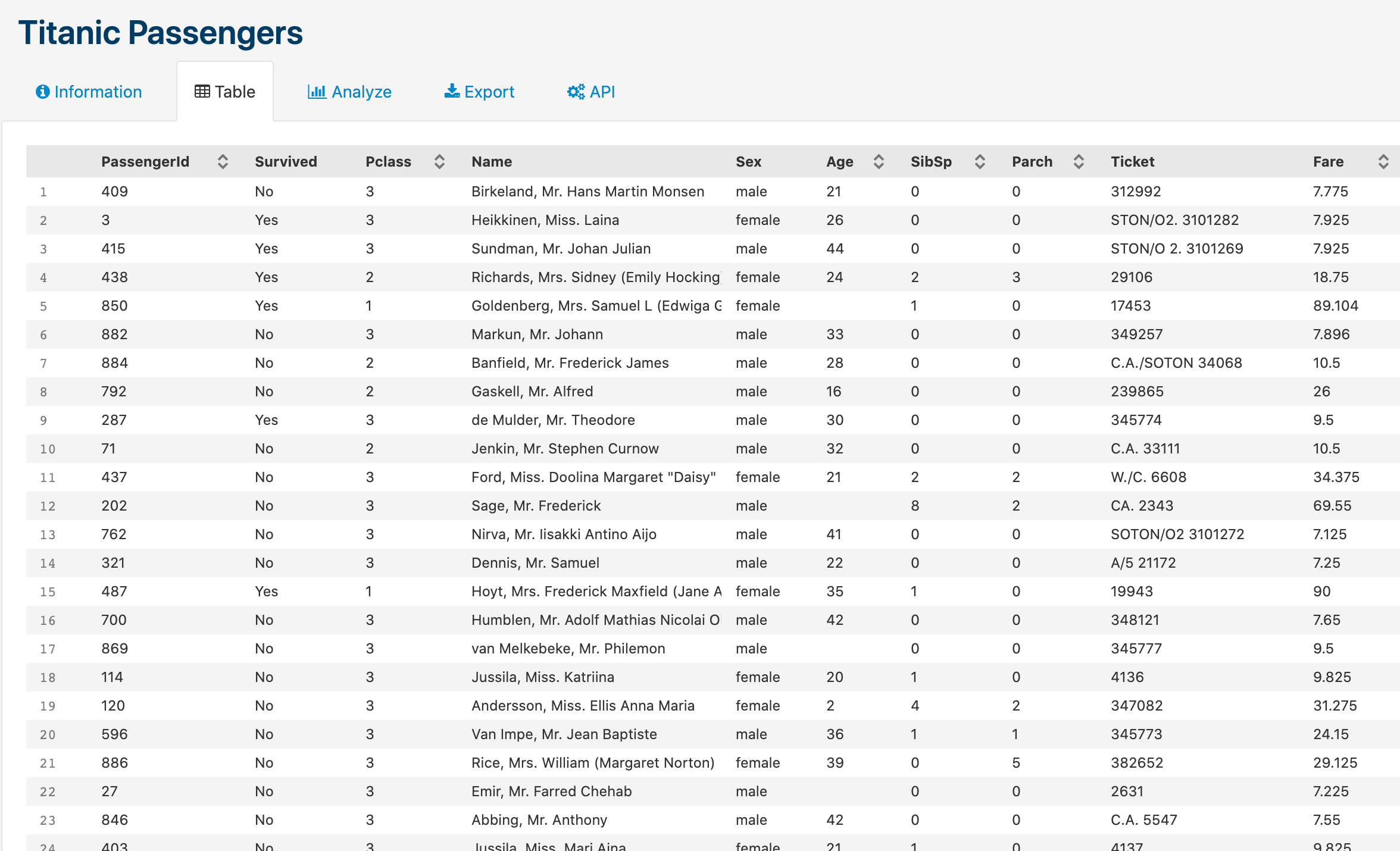 Dataset público sobre los pasajeros del Titanic
Dataset público sobre los pasajeros del Titanic
El algoritmo
Un algoritmo es un conjunto de instrucciones y cálculos, que, dados unos datos de entrada, obtendremos unos resultados de salida. En función del tipo de datos que disponemos, tendremos a nuestra disposición una gran cantidad de algoritmos que, en función de nuestros objetivos y predicciones que deseamos realizar, nos darán mejores o peores resultados. En nuestro caso, el algoritmo serían los cálculos que nos permitirían relacionar o determinar si un pasajero del Titanic falleció o no (en función de edad, sexo, clase en la que viajaba, etc.). Cuanto mas preciso sea nuestro algoritmo, mas precisos serán los resultados obtenidos.
 Representación gráfica de algunos algoritmos.
Representación gráfica de algunos algoritmos.
El modelo de aprendizaje
Una vez tenemos los datos y un algoritmo para clasificarlos, procedemos a combinarlos para obtener lo que llamamos un Modelo de Aprendizaje. Éste elemento (que podemos imaginarlo como una “bola mágica” en la que introducimos datos y recibimos predicciones), nos permitiría introducir nuevos “pasajeros” con todas sus características y obtener una predicción con un porcentaje de acierto X sobre si hubiese muerto o no en el Titanic.
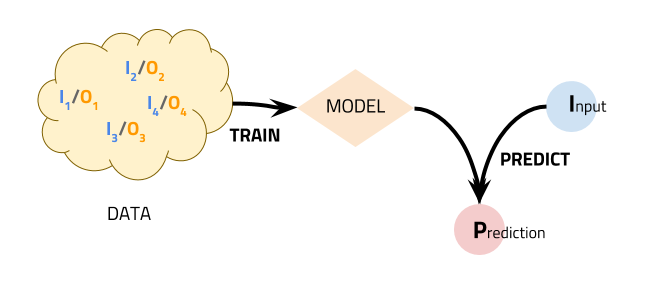 Modelo de aprendizaje en Machine Learning
Modelo de aprendizaje en Machine Learning
Por lo tanto, mediante un gran volumen de datos (registro de todos los pasajeros del Titanic), un algoritmo (cálculos para determinar si un pasajero sobrevivió o no), podemos obtener un modelo entrenado para realizar predicciones sobre si hubiésemos sobrevivido al hundimiento del Titanic (¿Qué surrealista, no?).
Y todo esto... para qué?
Muy interesante el hundimiento de un barco en 1912, pero... y ahora que?
Nos encontramos en la era digital, y eso se traduce en** ingentes cantidades de datos** producidas por nuestra empresa, sea cual sea el ámbito de la empresa y su tamaño. Éstos datos pueden ir desde información de nuestros clientes, transacciones que realizan, transacciones que realizamos, visitas, búsquedas, clics, peticiones, etc. LA CASUÍSTICA ES INFINITA.
Para una persona, es imposible analizar tal cantidad de datos y aún menos, realizar alguna predicción sobre estos. Los algoritmos en cambio sí pueden detectar patrones de comportamiento contando con las variables que le proporcionamos y realizar una predicción sobre un suceso.
Algunos ejemplos que se encuentran en nuestro día a día y no nos damos ni cuenta son:
- Control inteligente de los semáforos: Si tenemos los datos de tráfico de nuestra ciudad, podemos determinar cual es el mejor funcionamiento de nuestros semáforos para reducir los atascos.
- Detecciones de rostro: Si tenemos datos de miles de caras, podemos crear un modelo que determine rasgos de una persona o su propia identificación.
- Vehículos autónomos: Si tenemos los datos de navegación de miles de vehículos, podemos crear un modelo de conducción autónomo en que el vehículo se mantenga en la vía de circulación respetando la velocidad y cumpliendo las leyes.
- Diagnósticos médicos: Si tenemos los datos de muchos pacientes que han padecido un tipo determinado de cáncer, podemos crear un modelo para determinar si un nuevo paciente puede padecer o no cáncer.
- Clientes potenciales de un producto: Si tenemos el historial de búsqueda de muchos clientes, podemos crear un modelo que permita recomendar nuevos productos y servicios.
¡Las aplicaciones son infinitas...!
Una granja de pepinos. ¿Ejemplo absurdo o genialidad?
Tal y como hemos comentado en el anterior apartado, las aplicaciones de este paradigma son infinitas y cada vez mas precisas (cada vez tenemos mas datos). Algunas de estas aplicaciones pueden parecer bastante evidentes (o como mínimo, las podemos intuir), por otra parte, existen aplicaciones que parecen surrealistas o que nunca habríamos imaginado
Por ese motivo, hoy os queremos hablar de Makoto, un ex diseñador de sistemas integrados de la industria automotriz japonesa. Makoto tubo que empezar a ayudar a su padre en la granja de pepinos de la familia debido a la cantidad de trabajo que tenían. Los primeros días de trabajo, Makoto se dio cuenta de la cantidad de tiempo que requería invertir en clasificar los pepinos en función de sus características, como son:
- Tamaño
- Forma
- Color
- Otros
Pese a que su padre se sentía muy orgulloso de su granja y los productos ofrecidos respecto la competencia, Makoto pensaba que no se podía realizar semejante inversión clasificar los productos simplemente, sino que debía invertir todo ese tiempo en mejorar la calidad del producto.

Es por eso que Makoto decidió investigar y trabajar en una solución para optimizar el tiempo que le llevaba a su padre realizar la clasificación de los productos. Como podréis adivinar, la solución fue aplicar técnicas de Machine Learning. Utilizando herramientas disponibles en el mercado (las cuales facilitan mucho el proceso de aprendizaje), Makuto entreno un modelo de Machine Learning con ejemplos de mas de 7.000 pepinos con sus respectivas propiedades: El resultado:

Con este modelo y el sistema de la imagen anterior, Makuto consiguió un sistema automatizado para clasificar los productos con mas de un 75% de precisión. Este rango de precisión, a algunos les parecerá mucho, a otros poco, ¡pero lo importante es que se puede mejorar! A más datos que pueda introducir en el sistema de aprendizaje, mejor precisión obtendrá.
Como podemos ver, las aplicaciones de Machine Learning estan mucho mas presente de lo que nos imaginamos y percibimos en nuestro día a día. Y esto solo es el principio…
Fuentes y enlaces relacionados:
https://cloud.google.com/blog/products/gcp/how-a-japanese-cucumber-farmer-is-using-deep-learning-and-tensorflow
https://www.tensorflow.org/
https://cloud.google.com/blog/products/gcp